


What is Computer Vision?
Humans rely on their eyes to gather and interpret information, letting them understand their environment to execute actions properly. This "simple" action involves visual data collection and real-time interpretation. However, even though human vision is remarkable, it has limits, especially regarding errors or fatigue. In the end, we are not machines.
So, what is Computer Vision? If we dissect the term "Computer Vision," it essentially signifies what a computer can perceive. Therefore, we can consider Computer Vision to be the eyes of a machine powered by an artificial intelligence system. Similarly, these "eyes" allow machines to observe, analyze, and comprehend, ultimately understanding their environment as humans do. However, contrary to human vision, these "visual senses" are powered by cameras and sophisticated algorithms that can swiftly and accurately analyze data.
Computer Vision systems can process thousands of images or videos within minutes while identifying defects or irregularities. This surpasses human capabilities in speed and efficiency as CV can significantly reduce its margin of error, leading to more accurate and reliable outcomes in high-volume operations.
The computer vision market has been thriving for the last few years. With a projected annual growth rate (CAGR) of 11.69% from 2024 to 2030, the market size will reach US$50.97 billion by the decade's end.
How does Computer Vision work?
Let’s see how Computer Vision technology works. In short, developing Computer Vision algorithms, or “Computer Vision models” typically follows three steps:
- Acquire visual data (e.g., pictures or videos) and manually annotate it with the objects you intend to recognize later on.
- Train the Computer Vision model to understand what those objects look like to recognize them on new unseen images
- Use the trained Computer Vision model to automatically predict those objects on the flow of production images at scale.
Said like this, Computer Vision seems easy, right? Well, these “simple” steps are actually quite complex! Let’s dive deeper into the subject.
Images are represented digitally as a matrix of pixels, each containing values for the three primary colors: red, green, and blue (RGB). These values range from 0 to 255, where 0 represents complete darkness and 255 represents full brightness. All pixels come together to form the digital image. Here is a simple representation:

Source: ConnectCode
Another way to visualize how these pixels come together into a single image is to break down the image into a matrix showing the value of each pixel. Here is a representation of Andy Warhol’s “Marilyn Diptych” paint:
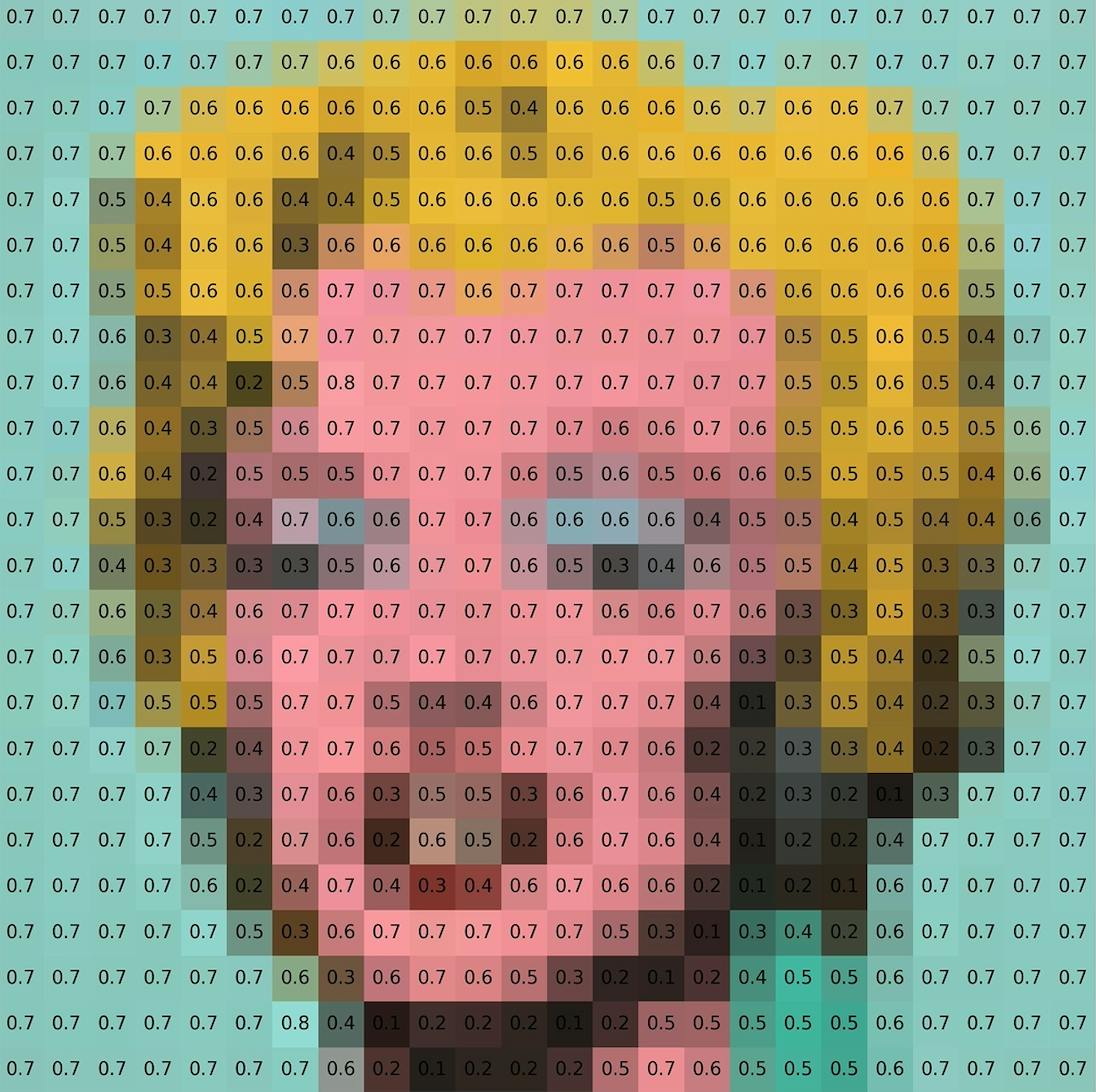
Keeping in mind how images are represented, we proceed to understand how Computer Vision systems process them. Two pillar technologies allow Computer Vision to recognize images and what is inside: Deep Learning and Convolutional Neural Networks (CNNs).
Deep Learning (DL)
Deep Learning is a type of machine learning that uses specific algorithms called Neural Networks. These networks are inspired by how our brains work, with interconnected layers of "neurons." DL is excellent at learning from vast amounts of data to find complex patterns similar to human capacities. It is possible because it allows computers to learn independently after analyzing contextual datasets.
Convolutional Neural Networks (CNN)
CNNs are a specific family of neural networks especially suited for processing image or audio data. Inspired by how the retina works in our eyes, they work by applying spatial filters to the image pixels (an operation called “convolution”).
Each filter is responsible for producing a signal specific to a visual pattern. By applying this operation several times, the model can recognize more and more complex shapes, ultimately resulting in the identification of the image's content itself.
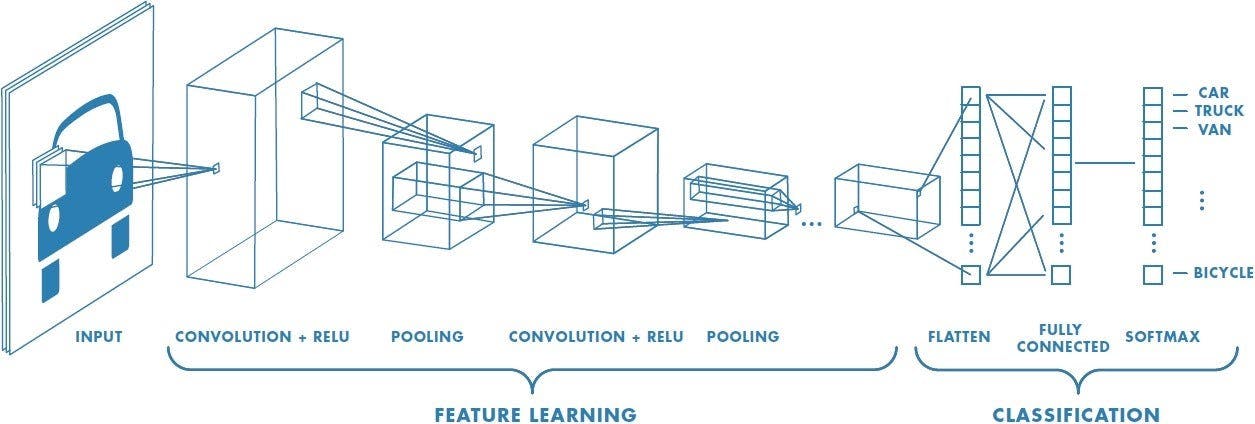
Source: Towards Data Science
Training the model involves adjusting filters to minimize errors on annotated images, enabling accurate identification of target objects in new images without manual intervention. Taking the example above, it means allowing a computer to learn how to recognize car pictures without human help.
Common Computer Vision Tasks
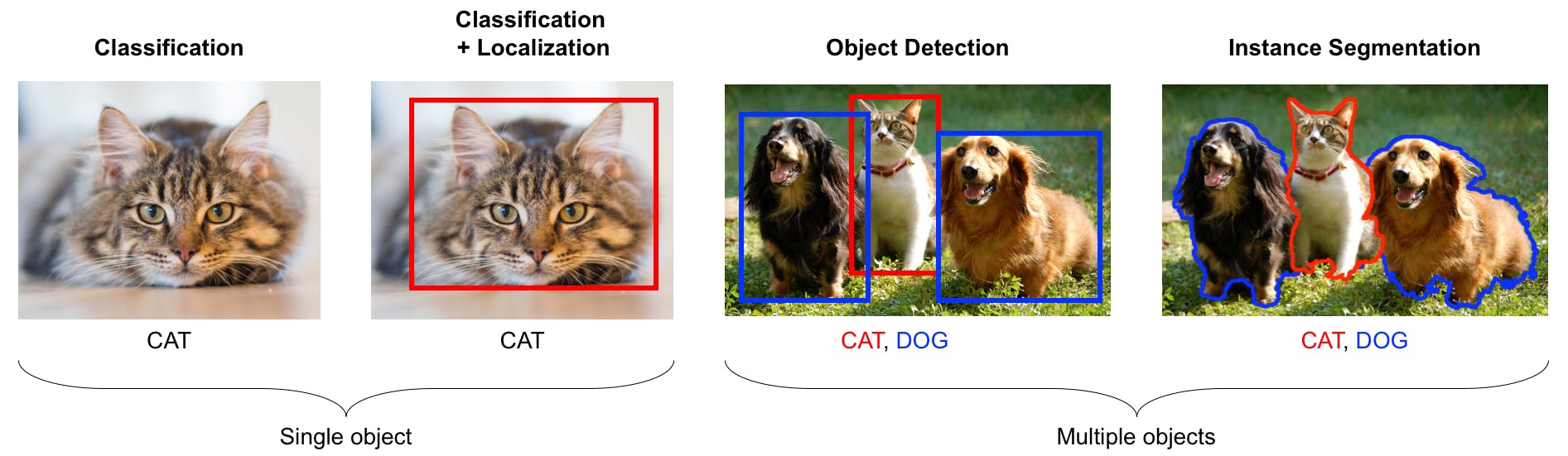
Image Classification
Image classification is a common task that categorizes an image among a set of pre-defined categories. It's been a hot topic since the release of ImageNet in 2010. The idea is straightforward: provide example images for each category, train the model, then let Computer Vision model categorize the new images.
Object Detection
Object detection is about finding and pinpointing objects in images or videos using boxes. The Computer Vision model is trained to recognize a specific set of target objects, like cars or people, and marks where they are in the picture with a rectangle.
Image Segmentation
Image segmentation is similar to “Object Detection”, but instead of localizing objects with a box, it localizes objects with their precise outline.
Optimal Character Recognition (OCR)
Optical character recognition or OCR is the capacity to read text on a picture. The Computer Vision model is able to convert the picture of some text into the actual list of characters and/or numbers.
Landmark/Keypoint detection
Keypoint detection is similar to object detection, but the model can also localize the precise location of some specific attributes. For example, when detecting faces, the model might also be able to localize the eyes, the nose, and the mouth.
For some tasks relying on the precise location of a point in space, it works better than detection because it can leverage the geometric consistency of the object to improve the precision of the prediction.
Computer Vision History
We have been talking a lot about what Computer Vision is, how it works, and some of the common tasks this technology performs, but when did it even start?
The origin
The very origin of Computer Vision dates back to 1957 when Russel Kirsch asked: What would happen if computers could look at pictures? This question led to Kirsch’s group creating the first digital scanner, thus generating the first digital image.
A couple of years later, in 1959, two neurophysiologists discovered by accident that the starting point of image processing was simple structures like straight edges. These findings resulted from a “Receptive fields of single neurons in the cat's striate cortex study” by David Hubel and Torsten Wiesel.
Computer Vision in the 1960s
The following decade experienced two big moments. First, artificial intelligence became an academic field of study, with many researchers advocating for its development. Indeed, AI was founded in the summer of 1956 during the Dartmouth College conference but only boomed in the 1960’s.
Secondly, in 1963, Lawrence Roberts was able to turn 3D information into 2D information, reducing the visual world into regular geometric shapes. His Ph.D. thesis, “Machine Perception of three-dimensional Solids,” described this process.
Computer Vision in the 1970s
The 1970s were the period where the groundwork for Computer Vision was developed, as researchers dived deeper into algorithm development for feature extraction (key points identification) and edge detection (object recognition) on images. This was also when industry players started to test computer vision for quality control (roots of visual inspection).
Computer Vision from 1980 to the end of the Millennium
During the 80s, two big contributions were made to the computer vision field. The first is David Marr's introduction to hierarchical models, which focuses on detecting edges, corners, curves, and similar basic shapes.
Over the same period, Kunihiko Fukushima developed Neocognitron, a technology that works on pattern recognition. Little did he know that his finding would be the starting point of Convolutional Neural Networks (CNN), core to today's computer vision.
Towards the end of the millennium and after years of research based on Marr’s work, there was a shift in the researcher's approach to Computer Vision. They stopped trying to reconstruct objects through 3D models and instead focused on feature-based object recognition. Parallely, the launch of LeNet-5, an essential ingredient for CNN’s, still used today.
Computer Vision from the 2000s onwards
During the early 2000s, massive study results floated to the surface. Findings like the first real-time face recognition (Paul Viola and Michael Jones, 2001) and standardized datasets for object classification (Pascal VOC) appeared. Then, in 2011, ImageNet happened. An enormous data set with over a million images, all manually tagged, featuring around a thousand object classes.
Two years later, Alexnet appeared during an image recognition competition. The model achieved a 16.4% error rate compared to former “records” of around 26%. Since then, error rates have dropped substantially and will continue to do so.
Computer Vision Applications
Telecommunications
Telecom operators have been using Computer Vision to address different use cases. Computer Vision has backed up the telecom industry for the last few years, from supporting teams constructing fiber optic networks to automating As-Built documentation and customer service.
Regarding fiber optic deployment, Computer Vision is a fundamental technology that can help telecom operators deploy their models faster thanks to instant feedback allowing quality control automation.
Utilities
In utilities, the primary usage of Computer Vision is to enable real-time monitoring and inspection of critical assets like power plants or wind turbines. Computer Vision is also used in smaller infrastructures, such as smart meter installation. In this case, the technology provides accurate meter readings, installation checks, and maintenance activities, ultimately enhancing SM installation speed.
Electric Vehicles Chargers (EVC)
Computer Vision develops companies' quality control processes to deploy and maintain EVC in the EV industry. The technology can guide technicians during interventions by identifying issues so that they perform maintenance tasks more efficiently.
Solar Panels
Like the EVC application, Computer Vision can optimize the installation process and provide predictive maintenance to keep solar panel infrastructures as good as new by flagging issues like panel obstructions or damages, ultimately improving energy efficiency.
Laboratories (Research)
In lab settings, such as in companies like Sanofi, Computer Vision is used for the surveillance of animals and automatic behavior analysis. This usage aims to speed up the testing processes and enhance the accuracy of results.
Automotive
Computer Vision technology has enabled the Automotive industry to reach new horizons, such as autonomous driving, accident prevention, driving behavior analysis, and quality control on the company’s assembly line.
Companies like Stellantis use computer vision to optimize their data handling for self-driving cars development and develop advanced safety features.
Food Service Industry
In the food sector, Computer Vision is used for self-checkout systems, enhancing customer experience and operational efficiency. It can identify items, calculate totals, and process payments automatically.
Manufacturing
In the manufacturing industry, Computer Vision is crucial in improving quality control, optimizing inventory management, and ensuring safety by monitoring production lines for defects or hazards and inspecting and assessing product quality to meet specified standards.
This industry is one of the pioneers when it comes to automated visual inspection.
Healthcare
In the healthcare industry, numerous applications have emerged, ranging from cancer detection to patient monitoring. Here's a non-exhaustive list of some key use cases:
- Diagnostic Imaging
- Surgical Support & Guidance
- Tumor/Cancer Detection
- Patient Care
- Smart Operating facilities
Security
Computer Vision techniques are extensively used for facial recognition and surveillance systems, contributing to security enhancements in various settings, from public spaces to private properties.
Finance
In the finance industry, classic use cases include fraud detection, document verification, and improving customer service through automated systems.
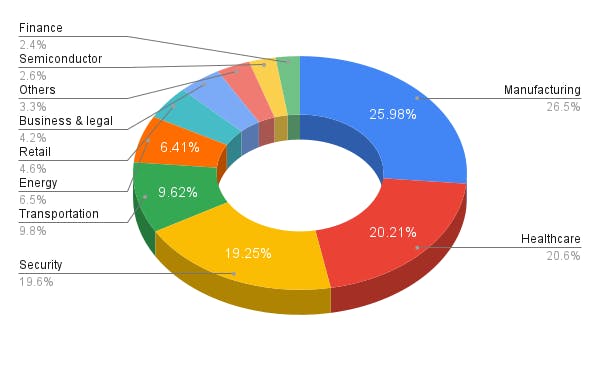
Computer Vision Market Share Division
Computer Vision's Technological Integration and Advancements
The Computer Vision models we described at the beginning of this post are called "fully supervised." This is because one needs to collect many examples of images annotated with the target objects we intend to teach to the model.
Emerging trends and future potential
A new wave of foundation models has emerged, propelled by the adoption of 'self-supervised' learning techniques. In this approach, the objective typically revolves around taking raw data, such as images or text, and training a model to reconstruct a portion of that data that has been intentionally concealed. Unlike traditional methods reliant on external manual annotations, this technique operates on existing data, where the masked segment is known to the training algorithm. This effectively circumvents the conventional bottleneck of necessitating human-labeled images for training. Consequently, it has paved the way for training significantly larger models on datasets several orders of magnitude larger than previously feasible. This includes training models on text, images, or videos sourced directly from the vast expanse of the internet.
These self-supervised models might reconstruct data in a latent space of "features" that abstractly represent the underlying data, like, for example, Meta's Dinov2 model, which was trained on 142 million pictures. Still, they can also try to reconstruct the original data directly (e.g., generate human-readable text or images), called "generative models." Those models are impressive because they produce very realistic text or images.
Another recent evolution is multi-modality. Until recently, computer vision depended on models trained on a single data type, like images. On the contrary, multi-modal models can jointly process data of various kinds, for example, by generating a video corresponding to a text description, enabling machines to understand the world better. This functionality unlocks a vast potential in human-machine interactions as people can instruct computers in human language to perform various tasks, implying the manipulation of all sorts of data (images, PDFs, curves and trends, etc…).
Computer Vision Challenges and Limitations
Like any growing technology, Computer Vision has challenges, from performance to biases.
Accuracy VS size challenges
When trained on sufficient data, the larger a deep learning model is, the more accurate it is. However, a large model consumes lots of memory and compute time. When deploying this model in a constrained environment, e.g., on mobile, memory and computing resources are limited.
To overcome this limitation, one can work towards two complementary directions to squeeze out the most from mobile hardware in terms of accuracy versus speed/memory tradeoffs:
- Reducing the model size with quantization and pruning techniques
- Relying on more mobile-friendly models which are designed from scratch for mobile.
Performance Challenges
It is necessary to have a well-defined problem you want to solve, and it's usually the most challenging part. If you spend a lot of time making a dataset and then realize you forgot something, you would have to go back to train that bit again. Despite these challenges, teams with great tooling can develop Computer Vision projects within a few weeks, encompassing dataset creation, training, and initial results.
Sensibility to bias
Machine learning models are susceptible to bias present in the training data. A notable example is the bias observed in some publicly available face detection algorithms, which tend to perform less accurately on people of color, particularly women, due to their under-representation in the training dataset. This phenomenon extends to various automated tasks, emphasizing the importance of detecting and addressing bias to enhance the accuracy and fairness of models.
Proprietary models and datasets
Since the surge of deep learning models in 2012, academic research has progressed rapidly, somewhat diminishing the advantage once held by proprietary models. However, this trend has shifted in the past 3-4 years with the exponential growth in the scale of both models and datasets.
This expansion necessitates immense computational resources for model training, a demand that often surpasses what academic funding can provide. Nevertheless, there has been a recent trend towards open-sourcing models and datasets. Certain organizations, such as Meta, Mistral, and Kyutai, have committed to this direction, enabling the research community to leverage their insights and advancements.
Computing power
The electric consumption associated with running deep learning algorithms is increasingly under scrutiny due to its contribution to carbon emissions. For instance, during the evaluation of models such as GPT-3, researchers discovered that over six months, they trained 4,789 model versions, consuming 9,998 days' worth of GPU time and emitting over 78,000 pounds of CO2.
Computer Vision Practical Insights and Learning Resources
Recommended Computer Vision Books
Are you looking to dive your nose into books the old-school way? Check our Computer Vision book selection!
Recommended Computer Vision Labs
Are you aspiring to become an expert researcher? Check our top Computer Vision-recommended labs!
Recommended Computer Vision Conferences
Looking to attend a Computer Vision conference but can’t decide which? Check our top CV conference pick!
Extra Computer Vision Ressources
There are several thousands of Computer Vision resources on the internet. Here are a couple of extra resources curated by the Deepomatic staff:
Blogs
- Lilian Weng (Open AI)
- Philipp Schmid (Hugging Face)
Youtube
- Andrej Karpathy (Open AI employee, explains how to build transformer model from scratch)
- Sentdex (Building Machine Learning from scratch)
- 3blue1brown (Computer Science, Maths, Physics channel with visual explanations)



