

Computer vision is becoming a must-have in field operations industries, as it allows to perform real-time quality control. To describe it simply, it is tempting to describe it as an image recognition technology, but careful, as they are distinct concepts, each playing a big role in AI. To clarify the nuances and intricacies between these two conflated terms, this article will delve deeper into their definitions, applications, as well as its relation.

Computer Vision: The Broader Scope in AI
Computer vision is a branch of artificial intelligence (AI). It is often referred to as the "eyes" of AI. Computer vision represents an ensemble of techniques aimed at automating multiple tasks by interpreting and understanding the content of digital images or video streams.
The capabilities of computer vision extend beyond mere image analysis. It encompasses a wide spectrum of functionalities including, but not limited to, optical character recognition (OCR), facial recognition, and iris recognition, each serving unique and transformative purposes:
Optical Character Recognition (OCR)
OCR technology is instrumental in converting documents, such as scanned paper documents, PDF files, or images captured by a digital camera, into editable and searchable data. This technology is key when digitizing printed texts, enabling efficient data processing and management.
Facial Recognition
As the name suggests, this technology involves recognizing and verifying a person's identity based on their facial features. Its applications are vast, ranging from enhancing security systems to advancing the fields of biometrics and robotics.
Iris Recognition
Another facet of biometric identification, iris recognition, involves identifying individuals based on the unique patterns of their irises. Given the complexity and uniqueness of iris patterns, this technology is renowned for its reliability and precision in security applications.
Here is a diagram to help you understand the hierarchy between these different fields of study.
As you can see from the diagram above, computer vision is not only about image recognition. Indeed, computer vision also encompasses optical character recognition (OCR), facial recognition, and iris recognition.
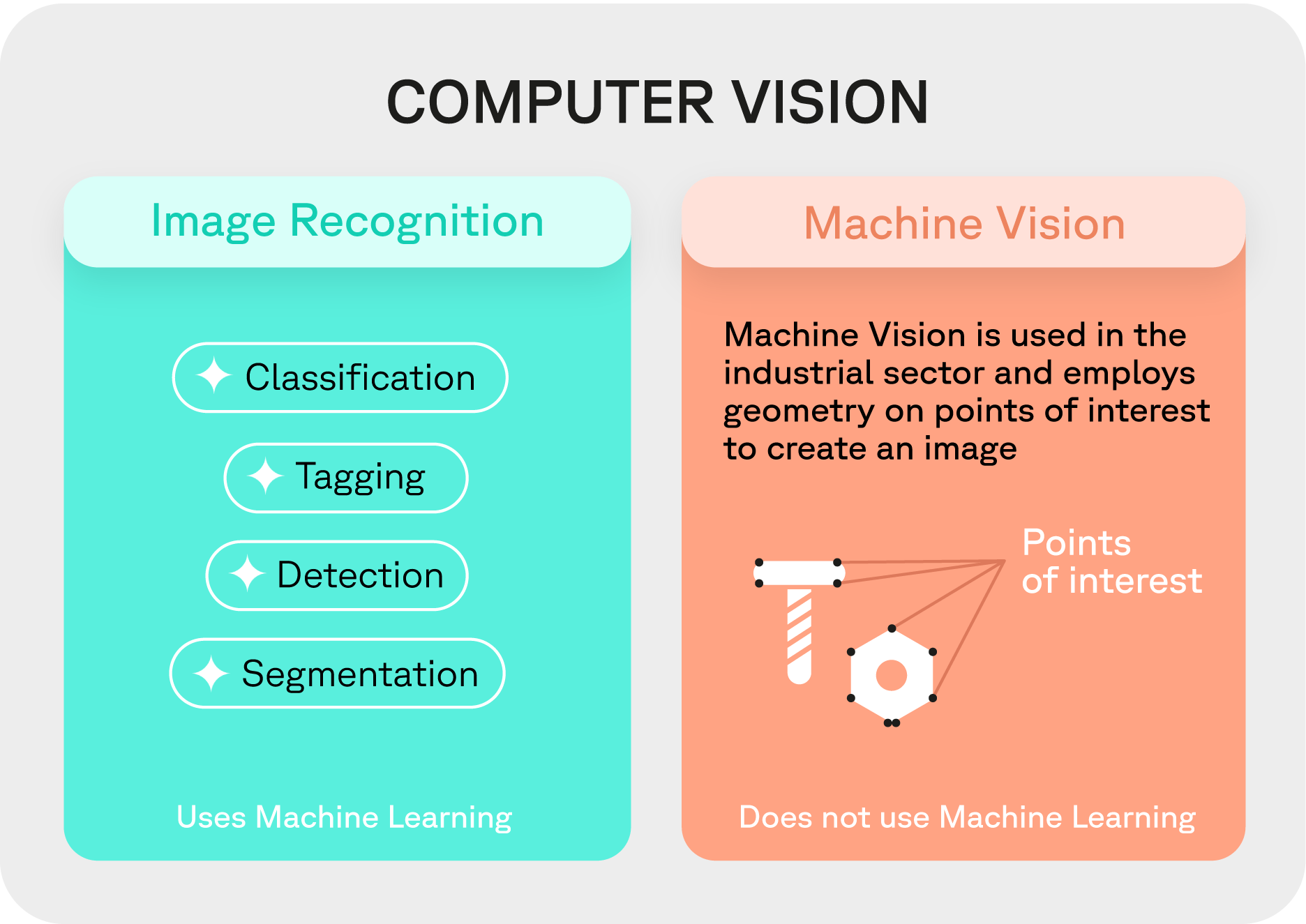
Image recognition, on the other hand, is a subset of computer vision. It consists of techniques for detecting, analyzing, and interpreting images to favor decision-making. It works through a neural network trained via an annotated dataset.
Image Recognition: A Specialized Subset of Computer Vision
Diving into the specifics, image recognition is a specialized subset within the broad umbrella of computer vision. It entails a series of methodologies aimed at identifying and deciphering the content of an image or a part of an image. Image recognition systems, powered by neural networks trained on extensively annotated datasets, are adept at tasks such as:
Image Tagging
Assigning relevant tags or labels to images, facilitating efficient organization and retrieval.
Object Detection
Locating and identifying objects within an image. Crucial for numerous applications, including surveillance and autonomous vehicles.
Segmentation
Dividing an image into segments to simplify and/or change the representation of an image, making it more meaningful and easier to analyze.
Image Recognition and Computer Vision, in short
Computer Vision
A broad branch of AI, computer vision involves automating tasks from images or video streams. It's the "eyes" of AI, encompassing various techniques beyond image analysis.
Image Recognition
A subset of computer vision focusing on detecting, analyzing, and interpreting images for decision-making. It includes tasks like image tagging, object detection, and guiding autonomous vehicles using neural networks trained on annotated datasets.



