


La Computer Vision et la reconnaissance d’images sont deux termes souvent associés et même confondus, alors qu’il existe bien une différence (subtile, mais existante !). Nous avons donc décidé de vous expliquer la nuance entre ces deux notions.
Qu’est-ce que la Vision par Ordinateur ?
La Vision par Ordinateur (Computer Vision) est une branche de l’Intelligence Artificielle. Son objectif est de permettre aux ordinateurs d’interpréter des données visuelles, comme les photos ou les vidéos, pour en extraire des informations.
Ces données visuelles proviennent de divers capteurs, notamment des caméras de vidéosurveillance ou des smartphones de techniciens de terrain. La Computer Vision englobe plusieurs branches, principalement la reconnaissance d’image et la Machine Vision.
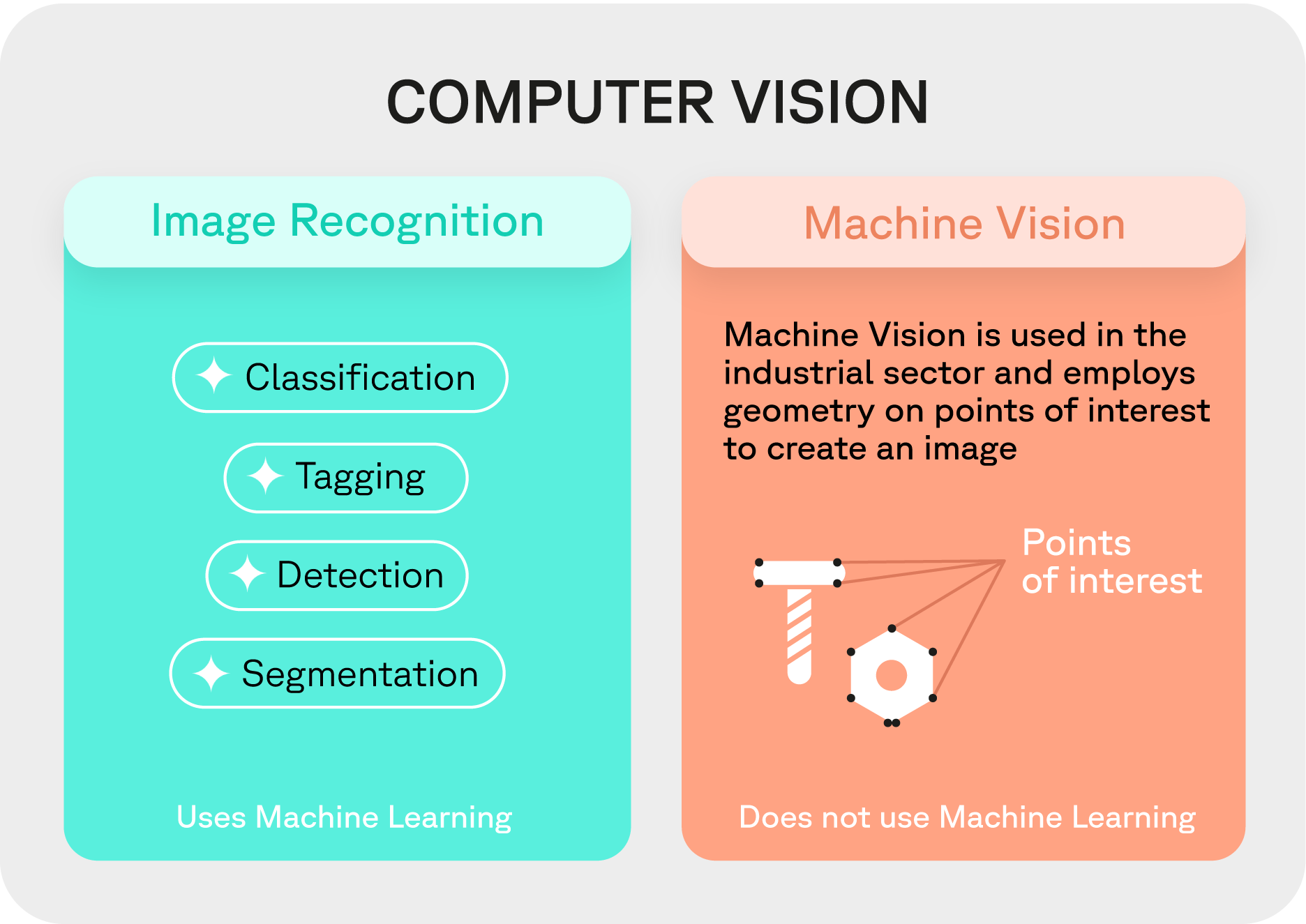
La reconnaissance d’image, domaine de spécialisation de Deepomatic, comprend plusieurs techniques :
- Classification : Attribution d’une catégorie unique à chaque image, parmi un ensemble prédéterminé.
- Tagging (ou classification multi-classes) : Attribution d’aucune, une ou plusieurs catégories à une image.
- Détection : Localisation d’un ou plusieurs objets d’intérêt dans une image ou une vidéo, avec délimitation par un rectangle (bounding box).
- Segmentation : Version plus précise de la détection, identifiant les éléments de l’image au pixel près et cartographiant chaque objet très précisément.
- OCR (Optical character recognition) : Reconnaissance et traduction en texte de données visuelles de textes imprimés ou dactylographiés.
Ces techniques s'appuient sur des algorithmes d’apprentissage supervisé. Ces algorithmes sont entraînés à partir d’images annotées par les concepts à reconnaître. Ils peuvent ensuite prédire ces concepts dans de nouvelles images jamais vues auparavant.
Enfin, la Machine Vision, différente de la reconnaissance d’image, reste une composante de la Computer Vision. Principalement utilisée dans le secteur industriel (par exemple, pour la standardisation de la découpe du métal), cette technique s'appuie sur l’identification de points d’intérêts prédéfinis et l'utilisation de la géométrie dans des algorithmes complexes pour déterminer la forme des objets.
Deux techniques de Vision par Ordinateur avec leurs avantages et inconvénients.
La différence fondamentale entre les techniques de reconnaissance d’image et de vision industrielle réside dans l’utilisation du Machine Learning pour la première, tandis que la seconde ne l'utilise pas. Le Machine Learning permet à un ordinateur “d’apprendre” à partir de données, c'est-à-dire de résoudre des tâches sans avoir été explicitement programmé pour le faire.
Vision Industrielle
La vision industrielle offre plusieurs avantages :
- Indépendance d'entraînement : Contrairement à la reconnaissance d’image, son système n’a pas besoin d’être entraîné, permettant une mise en place sans collecte de données d’entraînement au préalable.
- Adaptabilité : Utilisant des principes géométriques, la solution peut s'adapter à de nombreux sujets.
- Fiabilité : La géométrie offre une fiabilité élevée grâce à ses principes immuables.
Cependant, elle présente également des inconvénients :
- Complexité de mise en place : La création d'algorithmes géométriques complexes nécessite un expert.
- Rigidité : La rigidité des algorithmes rend la technique peu adaptable. Pour chaque nouvelle situation, un nouvel algorithme doit être créé.
Reconnaissance d'image
La reconnaissance d’image, basée sur le Machine Learning, présente des avantages distincts :
- Flexibilité : Elle est flexible et s'adapte rapidement à divers secteurs grâce aux réseaux de neurones.
- Accessibilité : Elle ne nécessite pas d'expertise spécifique. La collecte d'images ou de vidéos suffit pour la mise en place.
- Fiabilité : Avec des réseaux de neurones bien entraînés et des données correctement annotées, cette technique est très fiable.
Cependant, elle comporte aussi des inconvénients :
- Besoin en données : Pour être efficace, elle nécessite environ 1000 images par type d’objet pour l'entraînement.
- Travail préparatoire important : La mise en place exige un travail conséquent en amont, mais elle permet une adaptation facile aux évolutions, contrairement à la vision industrielle.
Et le Deep Learning dans tout ça ?
Avant 2015, le Deep Learning ne s’imposait pas, car cette technique était moins fiable et plus lente. Cependant, avec les progrès techniques et les développements de la recherche, le Deep Learning s’est considérablement renforcé. Les algorithmes de Deep Learning sont une branche particulière au sein de la famille des algorithmes de Machine Learning qui permettent à l’Intelligence Artificielle d’apprendre par elle-même à reconnaître des concepts, sans programmation, c’est-à-dire sans se contenter d’exécuter des règles prédéfinies.
La spécificité des algorithmes de Deep Learning tient au fait qu’ils sont basés sur des réseaux de neurones artificiels, calqués sur la structure du cerveau humain. Un réseau de neurones est constitué de plusieurs couches de neurones interconnectés qui permettent le traitement des données pour produire une analyse de la donnée fournie en entrée, comme une image. Contrairement aux algorithmes traditionnels composés de plusieurs étapes indépendantes, cette structure particulière permet d’entraîner le réseau de neurones de « bout-en-bout », c’est-à-dire des données jusqu’à la prédiction finale, ce qui débouche sur de bien meilleures performances.
Le rapide développement du Deep Learning a permis d’accélérer le développement des technologies sur lesquelles il se base, si bien que l’utilisation du Deep Learning est maintenant possible même sur du matériel peu gourmand en énergie comme les mobiles ou l’IoT.
De plus, cela a permis de rendre bien plus efficaces et précises des applications de la Computer Vision comme l’OCR ou la Pose Estimation :
- L’Optical character recognition est un technique permettant de transformer le texte présent sur une photographie en fichier texte.
- La Pose Estimation est une technique permettant de prédire numériquement comment l’utilisateur va influencer la transformation d’un objet.



