

The International Conference on Computer Vision (ICCV) stands as a cornerstone in computer vision research and development. Organized biennially, ICCV serves as a vital platform for the global community of computer vision scientists, researchers, engineers, and practitioners to convene, exchange knowledge, and showcase cutting-edge advancements in the field. With a rich history and a forward-looking vision, ICCV remains instrumental in shaping the trajectory of this rapidly evolving discipline and continues to be a catalyst for transformative breakthroughs in computer vision technology and its myriad applications in our modern world. The 2023 edition of ICCV was held in Paris from October 2 to 6, and our team attended the conferences, workshops, and tutorials that were organized to get immersed in the current and upcoming trends. If you are curious to get a recap of ICCV2023, stay on this article, and happy reading!
Towards more efficiency and accuracy with Vision Transformer (ViT)
In the quest for ever more performing algorithms, Vision Transformers have made their way. Unlike traditional convolutional neural networks (CNNs), which process images in a grid-like manner using convolutional layers, ViTs draw inspiration from the natural language processing (NLP) methods using Transformers architecture.
In a ViT, an input image is divided into fixed-size patches, which are then flattened and linearly embedded to form a sequence of vectors. These sequences are processed by a stack of transformer layers, which allow for capturing relationships and dependencies between different parts of the image. The self-attention mechanism in transformers enables the model to weigh the importance of each patch with respect to every other patch.
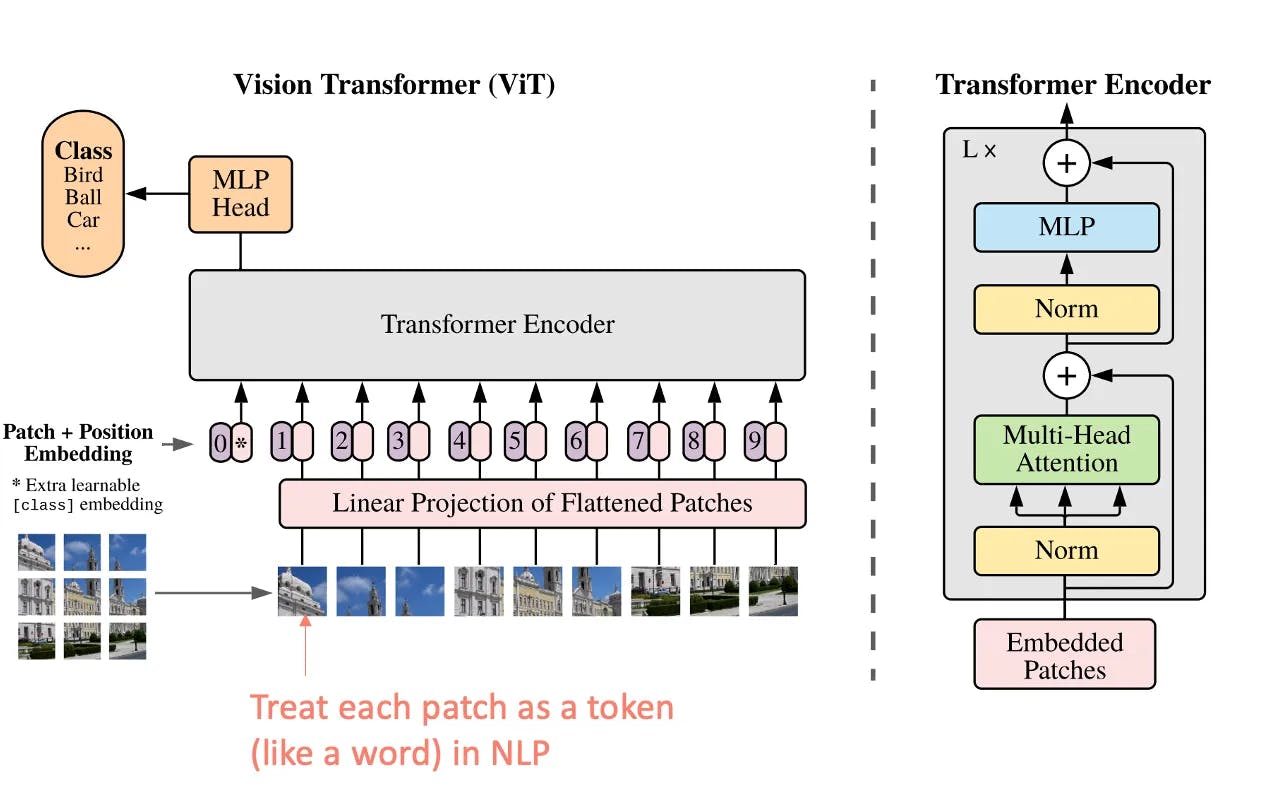
Transformer Architecture modified for images (ViT) (source)
CNNs excel in computer vision tasks with large datasets, while Vision Transformers shine in situations demanding global context. Nevertheless, Vision Transformers need more data for equivalent CNN performance, and CNNs are preferable for real-time, resource-limited applications due to their computational efficiency.
Multi-modal models: the hottest topic
Multi-modal models were practically on every lips at ICCV2023. But first, let’s explain what they consist of. Most of today’s computer vision models operate on data from a single modality: either images, text, or speech. However, real-world data often comes from multiple modalities: images with text or video with audio. To counter this challenge, researchers have developed multimodal machine-learning models that can handle data from multiple modalities, unlocking new possibilities for intelligent systems. Interestingly, the computer vision community is not only interested in fusing together images and text or image and sound but also other types of modalities such as temperature or depth.
This approach, which helps tackle complex computer vision tasks, has enabled significant progress in several areas, including:
- Visual question answering: this involves generating accurate answers to questions about an image
- Text-to-image generation: this involves training a model to generate images based on textual descriptions
- Natural language for visual reasoning: the aim here is to evaluate the ability of models to understand and reason about natural language descriptions of visual scenes
An obvious example of a multi-modal model covered at ICCV2023 is the CLIP (Contrastive Language-Image Pretraining) model. It opens new possibilities, such as the ability to make complex descriptions of the state of an industrial object. Indeed, when traditional computer vision models often categorize objects into discrete classes or labels, the CLIP model learns a more nuanced and contextual representation of visual information. It can grasp an image's subtleties, relationships, and contextual information rather than just recognizing objects as isolated entities.
If we draw a parallel with the primary capability of Deepomatic’s platform - the analysis of images captured by technicians and field agents to control their work automatically - we could go beyond a boolean understanding of the photos and, therefore, beyond a Yes or No approach to quality control.
New opportunities in video with egocentric vision
With the progress made in the efficient and deep understanding of images, new opportunities arise in the analysis of videos. In particular, some ICCV workshops discussed the emergence of analysis of egocentric videos, which consists of understanding visual data from the perspective of a person wearing or carrying a camera. It includes action recognition, scene understanding, gaze tracking, depth perception, contextual understanding, etc. It enables machines to understand visual data in a way that aligns with the natural perspective of humans.
By analyzing videos of technicians working in the field, and not just images before and after their job is completed, computer vision could derive valuable insights into the work that is carried out and deliver more comprehensive results on the quality of this work.
Foundation models: the pillar to democratize computer vision?
Foundation models have been emerging with auto-supervised machine learning. They are pre-trained neural network architectures that serve as a basis or starting point for a wide range of specific tasks within the domain of computer vision. These models are trained on large-scale datasets and have learned to extract meaningful features from images. These pre-trained foundation models provide a valuable starting point for many computer vision tasks and leverage high volumes of data. By fine-tuning these models on smaller, specific datasets for tasks like image classification, object detection, segmentation, and more, researchers and practitioners can achieve state-of-the-art performance with less data and computational resources compared to training a model from scratch.
Discussions at ICCV2023 showed that the promise to analyze images using open vocabulary and even basic logic was groundbreaking. However, the networks at play are much larger, and there is no consensus on the training strategies or the best way to manage the associated huge datasets. Additionally, because foundation models are used to build other models for a wide range of applications, it is very important to establish a regulatory framework, as any inaccuracies, biases, or flaws at the foundation model level may impact the downstream applications built from them. This framework should take into account the cascade effect of errors, the amplification of biases, the need for transparency and accountability, and ethical considerations.
The 2023 International Conference on Computer Vision (ICCV) showcased groundbreaking trends. Multi-modal models stole the spotlight, revolutionizing data processing across various modalities. Notably, CLIP exemplified nuanced visual understanding, going beyond conventional object recognition. Egocentric video analysis presented new perspectives, offering valuable insights for fieldwork. Vision Transformers (ViTs) marked a leap in efficiency and accuracy. Foundation models play a crucial role in democratizing computer vision, though challenges of scale and ethical considerations persist. ICCV 2023 reaffirms its pivotal role in shaping the future of computer vision.



