

L’International Conference on Computer Vision (ICCV) est un évènement incontournable dans le domaine de la recherche et du développement en vision par ordinateur (computer vision). Organisée tous les deux ans, l’ICCV sert de plateforme essentielle pour la communauté mondiale de scientifiques, de chercheurs, d’ingénieurs et de praticiens en vision par ordinateur pour se réunir, échanger des connaissances et présenter des avancées de pointe dans le domaine. ICCV continue de jouer un rôle essentiel dans la définition de la trajectoire de cette discipline en constante évolution, et demeure un catalyseur de percées transformatrices dans la vision par ordinateur et ses innombrables applications dans notre monde moderne. L’édition 2023 de l’ICCV s’est tenue à Paris du 2 au 6 octobre, et notre équipe a assisté aux conférences, ateliers et tutoriels organisés pour se plonger dans les tendances actuelles et à venir. Si vous êtes curieux de découvrir un récapitulatif de l’ICCV 2023, vous êtes au bon endroit ! Bonne lecture !
Vers plus d’efficacité et de précision avec les Visions Transformers (ViT)
Dans la quête d'algorithmes toujours plus performants, les Vision Transformers ont fait leur entrée. Contrairement aux réseaux de neurones convolutifs (CNN) traditionnels, qui traitent les images en grille avec des couches convolutionnelles, les ViTs s'inspirent des méthodes de traitement du langage naturel (NLP) en utilisant l'architecture des Transformers.
Dans un ViT, une image d'entrée est découpée en patches de taille fixe, qui sont ensuite aplatis et linéairement intégrés pour former une séquence de vecteurs. Ces séquences sont traitées par une pile de couches de Transformers, ce qui permet de capturer les relations et les dépendances entre différentes parties de l'image. Le mécanisme d'auto-attention des Transformers permet au modèle de pondérer l'importance de chaque patch par rapport à tous les autres.
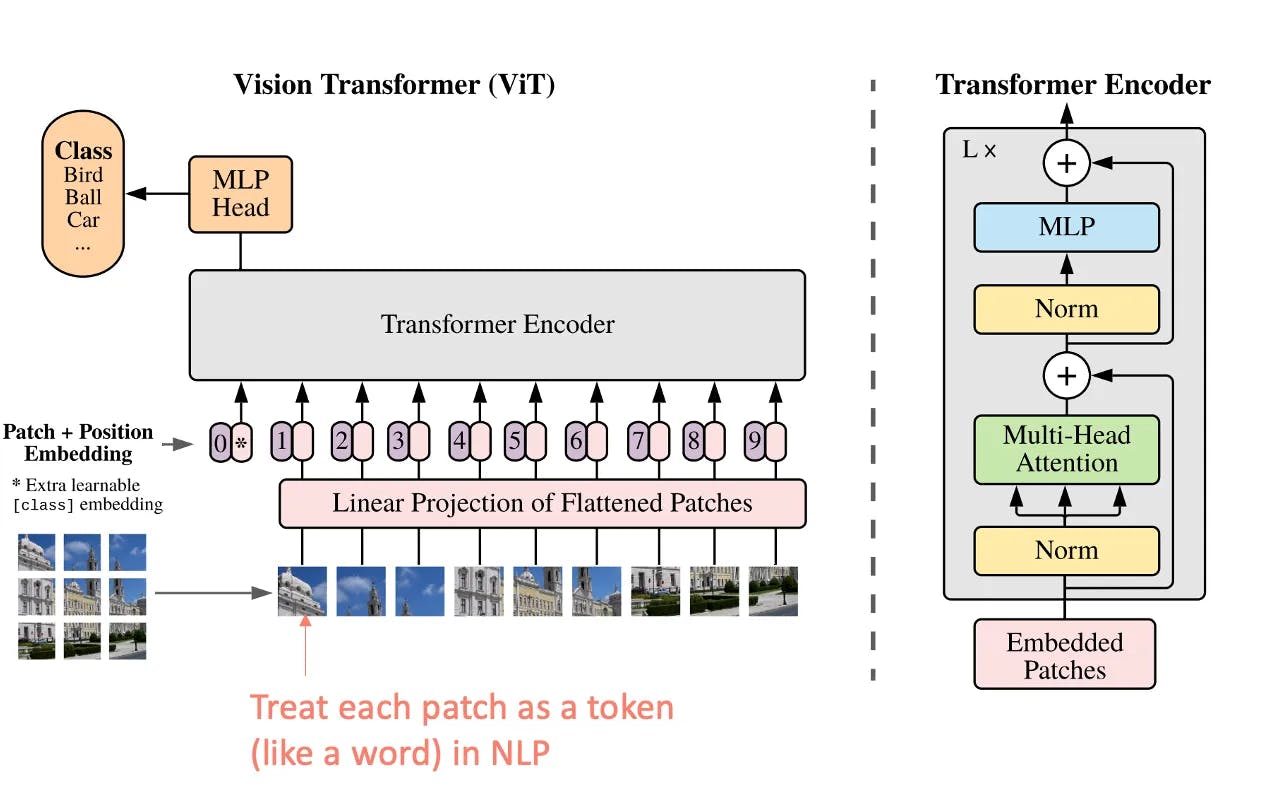
Architecture de Transformer modifiée pour des images (ViT) (source)
Les CNN excellent dans les tâches de vision par ordinateur avec de grands ensembles de données, tandis que les Vision Transformers brillent dans les situations exigeant un contexte global. Néanmoins, les Vision Transformers nécessitent plus de données pour obtenir des performances équivalentes aux CNN, et les CNN sont préférables pour les applications en temps réel et à ressources limitées en raison de leur efficacité computationnelle.
Les modèles multi-modaux : le sujet brûlant
Les modèles multi-modaux étaient pratiquement sur toutes les lèvres lors de l'ICCV 2023. Mais tout d'abord, expliquons en quoi ils consistent. La plupart des modèles de vision par ordinateur actuels traitent les données d'une seule modalité : images, texte ou parole. Cependant, les données du monde réel proviennent souvent de plusieurs modalités : images avec du texte ou de la vidéo avec du son. Pour relever ce défi, les chercheurs ont développé des modèles d'apprentissage machine multimodaux capables de gérer des données de plusieurs modalités, ouvrant de nouvelles perspectives pour les systèmes intelligents. De manière intéressante, la communauté de la vision par ordinateur s'intéresse non seulement à la fusion d'images et de texte, ou d'images et de son, mais aussi à d'autres types de modalités comme la température ou la profondeur.
Cette approche, qui contribue à résoudre des tâches complexes de vision par ordinateur, a permis des avancées significatives dans plusieurs domaines, notamment :
- Réponse aux questions visuelles : il s'agit de générer des réponses précises à des questions sur une image
- Génération texte-image : cela consiste à former un modèle à générer des images à partir de descriptions textuelles
- Langage naturel pour le raisonnement visuel : l'objectif est d'évaluer la capacité des modèles à comprendre et à raisonner sur les descriptions en langage naturel de scènes visuelles.
Un exemple évident d'un modèle multimodal, qui a été abordé à l'ICCV 2023, est le modèle CLIP (Contrastive Language-Image Pretraining). Il ouvre de nouvelles possibilités, comme la capacité à fournir des descriptions complexes de l'état d'un objet industriel. En effet, alors que les modèles de vision par ordinateur traditionnels catégorisent souvent les objets en classes ou étiquettes distinctes, le modèle CLIP apprend une représentation plus nuancée et contextuelle de l'information visuelle. Il peut saisir les subtilités, les relations et les informations contextuelles au sein d'une image, plutôt que de simplement reconnaître les objets comme des entités isolées.
Si nous faisons un parallèle avec la capacité principale de la plateforme Deepomatic - l'analyse d'images prises par des techniciens et des agents de terrain pour contrôler automatiquement leur travail - nous pourrions aller au-delà d'une compréhension binaire des photos, et donc au-delà d'une approche Oui ou Non pour le contrôle de la qualité.
De nouvelles opportunités en vidéo avec la vision égocentrique
Avec les progrès réalisés dans la compréhension efficace et approfondie des images, de nouvelles opportunités se présentent dans l'analyse des vidéos. En particulier, certains ateliers de l'ICCV ont discuté de l'émergence de l'analyse des vidéos égocentriques, qui consiste à comprendre les données visuelles du point de vue d'une personne portant une caméra. Cela inclut la reconnaissance d'actions, la compréhension de scènes, le suivi du regard, la perception de la profondeur, la compréhension contextuelle, etc. Cela permet aux machines de comprendre les données visuelles de manière alignée avec la perspective naturelle des humains.
En analysant les vidéos des techniciens travaillant sur le terrain, et pas seulement les images prises avant et après leur travail, la vision par ordinateur pourrait tirer des enseignements précieux sur le travail effectué et fournir des résultats plus complets sur la qualité de ce travail.
Les modèles fondamentaux : le pilier de la démocratisation de la vision par ordinateur ?
Les modèles fondamentaux émergent avec l'apprentissage automatique auto-supervisé. Ce sont des architectures de réseaux neuronaux pré-entraînées qui servent de base ou de point de départ pour un large éventail de tâches spécifiques dans le domaine de la vision par ordinateur. Ces modèles sont entraînés sur des ensembles de données à grande échelle et ont appris à extraire des caractéristiques significatives des images. Ces modèles fondamentaux pré-entraînés fournissent un point de départ précieux pour de nombreuses tâches de vision par ordinateur et exploitent de gros volumes de données. En affinant ces modèles sur des ensembles de données plus petits et spécifiques pour des tâches telles que la classification d'images, la détection d'objets, la segmentation, etc., les chercheurs et les praticiens peuvent atteindre des performances de pointe avec moins de données et de ressources computationnelles par rapport à l'entraînement d'un modèle à partir de zéro.
Les discussions à l'ICCV 2023 ont montré que la promesse d'analyser les images en utilisant un vocabulaire ou même une logique de base était révolutionnaire. Cependant, les réseaux en jeu sont beaucoup plus vastes et il n'y a pas de consensus sur les stratégies pour les former, ni sur la meilleure façon de gérer les énormes ensembles de données associés. De plus, comme les modèles fondamentaux sont utilisés pour construire d'autres modèles pour un large éventail d'applications, il est très important d'établir un cadre réglementaire, car toute inexactitude, partialité ou défaut au niveau du modèle fondamental peut avoir un impact sur les applications aval construites à partir d'eux. Ce cadre doit prendre en compte l'effet de cascade des erreurs, l'amplification des biais, la nécessité de transparence et de responsabilité, ainsi que les considérations éthiques.
ICCV 2023 à Paris a mis en avant des tendances cruciales en vision par ordinateur. Les Transformateurs de Vision (ViTs) révolutionnent le traitement d'images, offrant une approche transformative avec une efficacité accrue. Les modèles multimodaux ont émergé comme un thème dominant, débloquant de nouvelles possibilités en intégrant des données provenant de diverses sources. Notamment, le modèle CLIP a démontré une compréhension visuelle nuancée, surpassant la reconnaissance d'objets traditionnelle. L'analyse vidéo égocentrique promet des perspectives profondes, particulièrement pour le travail sur le terrain. Les modèles fondamentaux jouent un rôle crucial dans la démocratisation de la vision par ordinateur, bien que des défis d'échelle et des considérations éthiques persistent. ICCV 2023 a réaffirmé son rôle dans la stimulation de percées visionnaires dans ce domaine dynamique.



